What Are the New Data Lake Patterns
The concept of a traditional data warehouse is a very efficient one. Actually, it is so efficient that we have started using it to do all kinds of analytics. When we encounter challenging situations like changes to schema, excessive volumes and difficult identity resolution situations, the traditional approach falls short of expectations. An alternative approach, leveraging the concept of the data lake, referred to as “The Data Lake Pattern” has gained a lot of momentum. The data lake concept in itself isn’t new. It has been around for a few years now, just like blockchain.
James Dixon, the founder and CTO of BI software company Pentaho, famously described data lake this way, “If you think of a data mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake and various users of the lake can come to examine, dive in, or take samples.”
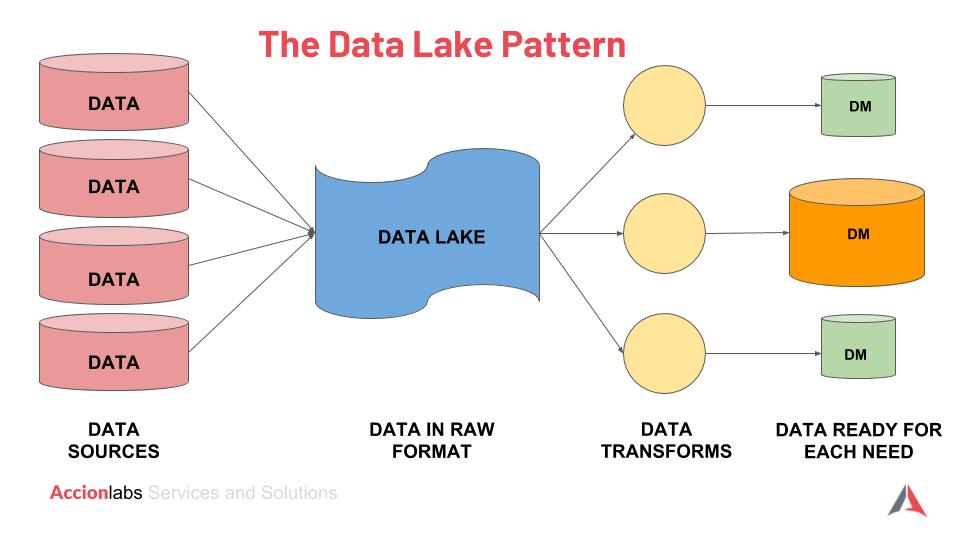
In a data lake:
- Data from all sources is retained - think of it as a large storage area that you have used to store all kinds of data. This is vastly different from a data warehouse that stores structured data alone - you have sorted/structured the items from a data lake - which is both time-consuming and expensive, and primarily takes into account current requirements.
- Data is stored irrespective of structure and source.
- Users can easily configure and reconfigure their data models due to its flexibility and agility.
- Security may not be at the same level as a data warehouse, but again the setup of a data lake may be more fluid than a data warehouse. For example, an organization may employ separate data lakes for storing ongoing production work data in one lake and data for data scientists in another. Interestingly, due to the nature of data lakes, organizations are largely deploying them on the cloud.
Data Lake Anti-patterns
While it all sounds great, according to Gartner, 80% of existing data lakes will become inefficient by the end of 2018. The following are a few anti-patterns that are resulting in ineffectiveness and finally failure of these data lake projects:
- Organizations build data lakes as a single platform for self-service, aimed at making it the universal source of data for information analysis. However, these data lakes turn into data swamps over a period of time, where data is stored and finally forgotten.
- Organizations tend to get carried away by the promise of big data vendors and make a lot of promises to businesses. They amass petabytes of data but with no business facing apps essentially turning into ‘data lakes to nowhere’.
- When disparate business units on different systems start writing to the data lake using different file formats and elements at different levels of granularity, the resulting challenge is that we have data, but there is no easy way to combine them for uncovering any actionable insights making the data too far out of reach.
- Organizations tend to build data lakes using one technology and then they introduce the next one and the next one. The problem stems from the fact that little to no consideration is given to what storage formats these technologies are utilizing and how the data is interchangeably useful with other technologies to a point where technologies are causing a technology stampede. As a result of this technology stampede, data gets locked in a maze. Companies need to use more than one technology to glean any meaningful insight.
- Sometimes, teams build models based on a small set of data and when they attempt to scale it beyond that small set of data, the data lake stagnates in prototype mode and fails when moved to production.
Data Lake Antidotes
While the previous section makes the data lake seem like a technological curse, the truth is far from it. What the data lake requires is an approach that is surgically precise and respects the vast amounts of data stored without simply considering it a dumping ground that will work efficiently when needed.
The data lake works best when:
- The data lake is accompanied by a semantic layer that helps clearly identify and locate data in the data lake.
- Metadata extraction, capture, and tracking are automated as data lakes rely on a clear set of attributes such as data lineage, data quality, and usage history - all of these define the quality of data in a data lake.
- You have a clear business goal and a firm understanding of your businesses’ larger analytical efforts and needs, and your data lake is designed to take advantage of both.
- Data projects are built upon a sound architecture and with a roadmap in mind.
- The business is fully engaged in every step of building the data lake and leveraging it for sourcing reports and analytics from the lake.
- Development is done iteratively and not in a haste.
The Ideal Data Lake
The title of the section sounds wishful, right? In a sense, it is; however, the ideal data lake does exist. Companies that emphasize business goals and models, and not the data lake itself build practical data lakes.
Our experience has taught us that building data lakes requires a disciplined, well-planned approach:
- Identify drivers, stakeholders and define goals.
- Assess current data assets to define the operating model, establish zones in the data lake.
- Determine the right tools for data analytics pipelines.
- Take time to define the different data zones (for example raw, sensitive, gold, work, etc.) for different classes of consumers (for example engineers, stewards, scientists, data analysts, etc.).
- Implement a packaged semantic (metadata) layer for the data lake or build your own.
- Build the data lake in iterations.
- After each step, check the alignment and repeat.
A data lake should be built for ‘now’. Data loses value over time, and “let’s store it all” is a poor approach. Even if you store all the data, be prepared to re-baseline data before you can use it.
Our Real-World Data Lake Experience
A well-known global retail giant was struggling with a significant amount of data, pegged at about 4.6 billion events every week. This data required processing in order to perform identity resolution. Additionally, processing of historical data with a one-time bulk load of ~30 terabytes of data/17 billion transactions was proving to be an arduous task. The company did not have any standardized data management processes in place. Hence, the quality of data was poor, inconsistent, duplicated, and in some cases missing.
We were approached by the retail firm and we discussed at length the myriad data problems and in partnership, we drew up an effective data management solution approach and executed it in an iterative manner. Some of the key highlights of the solution were:
- A highly scalable and elastic analytical platform that helped engineer massive performance improvements in the data lake.
- A concurrent, elastic, non-blocking, asynchronous architecture that would help the client reduce approximately 22 hours of runtime (down to about 8 hours from 30 hours) for 4.6 billion events.
- Improved master data management by performing identity resolution through fuzzy logic.
- Enhanced latency that helped augment productivity
- Clean datasets were used to deliver KPIs, raw datasets for machine learning and downstream applications through REST APIs.
Do you have a data problem? Does your existing data platform sound like one of the anti-patterns? Are you trying to build your own data lake?
We are a team of more than 100 data professionals - scientists, engineers, analysts, product and data architects - who can envision, plan, engineer and analyze to help uncover insights hidden in your data, thereby helping you unlock the true potential of your data.
Get in touch with us now.
