Performing Big Data Analytics using Apache Spark for .NET
All these tools and frameworks make up a huge Big Data ecosystem and will be difficult to cover in a single article. Hence, in this article we will cover what is Apache Spark, how can we use Apache Spark with .NET and its architectural framework.
What is Apache Spark
Apache Spark is a general-purpose, fast, and scalable analytical engine that processes large scale data in a distributed way. It comes with a common interface for multiple languages like Python, Java, Scala, SQL, R and now .NET which means the execution engine is not bothered by the language you write your code in.
Why Apache Spark
Let alone the ease of use, the following are some advantages that make Spark stand out among other analytical tools: Makes use of in-memory processing: Apache spark makes use of in-memory processing which means no time is spent moving data or processes in or out to disk which makes it faster.
It is extremely efficient: Apache Spark is efficient since it caches most of the input data in memory by the Resilient Distributed Dataset (RDD). RDD is a fundamental data structure of Spark and manages transformation as well as the distributed processing of data. Each dataset in RDD is partitioned logically and each logical portion may then be computed on different cluster nodes.
Real-time processing: Not only batch processing but Apache Spark also supports stream processing which means data can be input and output in real-time.
Adding to the above advantages, Apache Spark APIs are readable and easy to understand. It also makes use of lazy evaluation which contributes towards its efficiency. Moreover, there exist rich and always growing developer’s spaces that are constantly contributing and evaluating the technology.
Apache Spark for .NET
Until 2019, .NET developers were locked out from big data processing due to lack of .NET support. But on April 24, 2019, Microsoft unveiled the project called .NET for Apache Spark.
.NET for Apache Spark makes Apache Spark accessible for .NET developers. It provides high performance .NET APIs using which you can access all aspects of Apache Spark and bring Spark functionality into your apps without having to translate your business logic from .NET to Python/Scala/Java just for the sake of data analysis.
Apache Spark Ecosystem
Spark consists of various libraries, APIs, and databases and provides a whole ecosystem that can handle all sorts of data processing and analysis needs of a team or a company. The following are a few things you can do with Apache Spark.
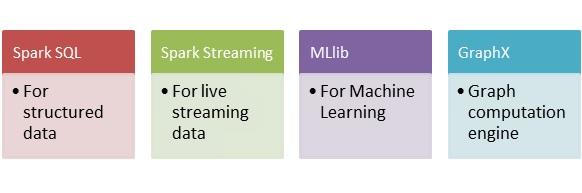
All these modules and libraries stand on top of Apache Spark Core API. Spark Core is the building block of the Spark that is responsible for memory operations, job scheduling, building and manipulating data in RDD, etc.
Apache Spark Architecture
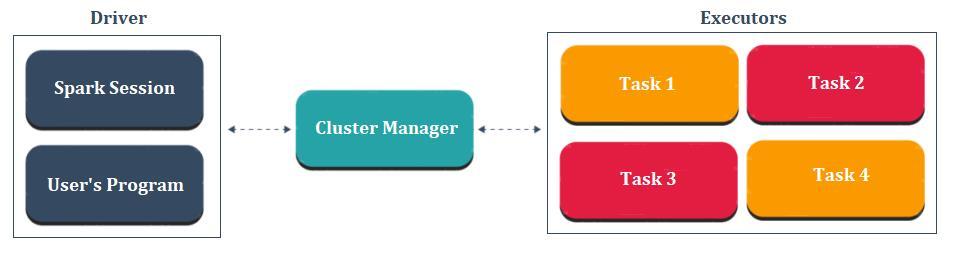
Apache Spark architecture follows the driver-executor concept. The following figure will make the idea clear.

Each Spark application consists of a driver and a set of workers or executors managed by the cluster manager. The driver consists of a user’s program and sparks session. Basically, spark session takes the user’s program and divides it into smaller chunks of tasks which are divided among workers or executors. Each executor takes one of those smaller tasks of the user’s program and executes it. Cluster Manager is there to manage the overall execution of the program in the sense that it helps diving up the tasks and allocating resources among driver and executors.
But what goes under the hood
When creating the application, both .NET Core and .NET Runtime can be used to create a Spark program. Why is that so? And what exactly is happening with our .NET Spark code? To answer that question, look at the following image and try to make sense of it.
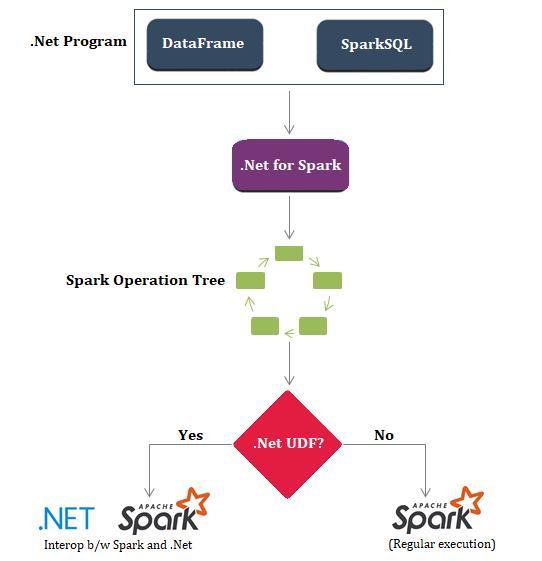
The jar files need to be added to the solution when Microsoft.Spark NuGet package is added. The NuGet Package adds .NET driver to the .NET program and ships .NET library as well as two jar files. The .NET driver is compiled as .NET standard, so it doesn’t matter much if you’re using .NET Core or .NET runtime while both jar files are used to communicate with the underlying native Scala APIs of Apache Spark.
Conclusion It’s easy to see that .NET implementation brings the full power of Apache Spark for .NET developers. Moreover, you can also write cross-platform programs using .NET for Apache Spark. Microsoft is investing a lot in .NET Framework. The .NET implementation of Apache Spark can also be used with ML.NET and a lot of complex machine learning tasks can also be performed. Feel free to experiment along.
