-for-your-business.jpg?width=575&name=Data_-Dimensional-Data-Modeling-(DDM)-for-your-business.jpg)
Dimensional Data Modeling is one of the methods of data modeling that helps us design a data model which is retrieval friendly. Let us try and build a crude model to understand dimensional modeling.
A friend once asked me this question: “Every month, we earn and spend money. I always keep wondering at the end of the month why there’s only so little left. How can I see where’s my money going”?
I told him to define his questions for me to answer. So here are his questions:
- How much money am I spending this month on basic amenities – such as food and accommodation?
- How much money am I spending on transportation?
- How much money am I spending on entertainment?
- How much am I paying at Costco every month?
- How much is my American Express credit card bill likely to be this month?
- Which restaurant am I visiting frequently?
So, let us take all of these questions and start defining a dimensional model to answer these questions.
The first important thing to dimensional modeling is the Questions.
If we look at all these questions, our answers will be measurable values such as – How much (money), How many (times). These measurable values are called Facts or Measures. We store these measurable values in tables called Fact Tables.
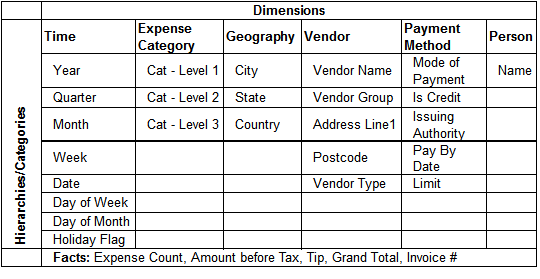
Now when we say 100 times or $5000, it does not make complete sense.We need to qualify these measures using some qualifiers or dimensions. Some of the dimensions to look at are:
- Time
- Expense Category
- Payment Method
- Vendor
- Geography
- Person
Each dimension has columns called attributes. These attributes provide characteristics of the qualifying dimension. These attributes can be related to each other forming a hierarchy such as time dimension wherein attributes can be Year, Quarter, Month, Week, Day etc., and the attributes are related through a hierarchy – Year → Quarter → Month → Week → Day.
Now, the magic of dimensional modeling is that it is designed to aid the reporting.
So, the dimensional model is almost always – a central fact table containing the measures and links to a series of dimensions each qualifying the measures in one particular way. This kind of model is called the Star Schema.
In the star schema design, a single object called a fact table sits in the middle and is connected to other surrounding objects called dimensions like a star. Each dimension is represented as a single table. The primary key in each dimension table is related to a foreign key in the fact table.
Below example is of a star schema.
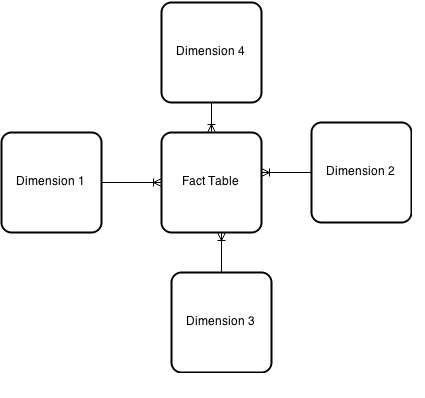
All the facts in the fact table are related to all dimensions that fact table is related to. i.e., they all have the same level of granularity. A simple star consists of one fact table; a complex star can have more than one fact table. The lines between two tables indicate that there is a primary key / foreign key relationship between the two tables. Note that different dimensions are not related to one another.
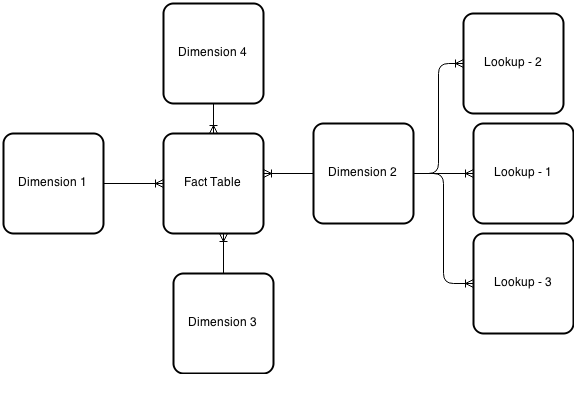
In a star schema, each dimension is represented by a single dimensional table. But if one or more dimensional table is normalized into multiple lookup tables, say, each representing a level in the dimensional hierarchy. Such a dimensional model is called snowflake schema.
Below is an example of a snowflake schema.
Now, let us discuss gathering requirements. As mentioned in the previous section we need to gather requirements by getting the business questions that need to be answered. The resultant step is to convert these questions into Information Packages:
Then, build a requirements specification document with the following sections:
- State the purpose and scope of the project. Include broad project justification. Provide an executive summary of each subsequent section.
- General requirements descriptions. Describe the source systems reviewed. Include interview summaries. Broadly state what types of information requirements are needed in the data warehouse.
- Specific requirements. Include details of source data needed. List the data transformation and storage requirements. Describe the types of information delivery methods needed by the users.
- Information packages. Provide as much detail as possible for each information package. Include in the form of package diagrams.
- Other requirements. Cover miscellaneous requirements such as data extract frequencies, data loading methods, and locations to which information must be delivered.
- User expectations. State the expectations in terms of problems and opportunities. Indicate how the users expect to use the data warehouse.
- User participation and sign-off. List the tasks and activities in which the users are expected to participate throughout the development life cycle.
- General implementation plan. At this stage, give a high-level plan for implementation.