
The purpose of business is to create a customer- Peter Drucker
In today’s highly competitive business landscape, the focus on understanding customer’s pain points and using that to change the product or service is becoming more and more important. Voice of the Customer (VoC) is a term that describes a customer’s feedback about experiences with and expectations for products or services. The purpose of a VoC is twofold:
Retain customers already created Improve products and services to attract new ones.
How Does VOC Work?
Nowadays, the VoC is conducted on a larger scale by leveraging the power of the internet using both solicited feedback — email, web intercept, SMS — and unsolicited feedback — social in particular — to listen to the voice of the customer. Building a holistic picture of the experience that you are to every customer enhances customer experience and increases business growth.
An opinion phrase is generally a term that people are generally interested in when reading a review. A lot of research has been done towards extracting Opinion phrases from customer review corpus using various approaches including LDA, Bag, and Words. The results vary based on the data they handle. In other words, VOC or Opinion Phrase is about revealing the analytics hidden under user reviews in an unstructured way. Often, the most important information that the customer provides never gets captured as important data points for decision making by the management.
Let’s take an example. A leading computer manufacturer had grievances regarding the CRM system and its inability to track precious customer feedback which adversely affected the management’s decision to act upon or improve the quality of products/services.They needed the following information on their customers
Which parts do the customers like/dislike Who are their loyal customers What other feature do the customers want in the product/service?
The NLP Approach
Let’s assume we have the following sample data required for this exercise
Product – “Mac pro” Source – “e-commerce Website” Rating – “4/5″Source – “e-commerce Website” Rating – “4/5″ Customer Review – “I have had this laptop a good few weeks now, tested it fully and know the positives and negatives. ..Screen is nice and wide, perfect for work, gaming and browsing the web. ..Audio is great, very loud and clear. The webcam is very nice, perfect for streaming, very high detailed with no ‘jittering. Ports are good, the HDMI works perfectly and looks great on my TV.
From an analytics standpoint, we would need a Natural Language Processing (NLP) engine that would slightly differ from the native approach as mentioned below :
- Data processing/analyzing
- Data cleansing
- Data augmentation
- Feature extraction.
- Data point for plotting/reporting
Data processing and analyzing is the slice and dice process of the given data. It often requires one to read the data multiple times and arrive at the hidden features present. This process helps to see the textual pattern for NLP process.
Data cleansing would remove any unnecessary data as well as an outlier unless otherwise, it can reduce the overall accuracy and outcome of the process. There are multiple ways to arrive at the outlier data with respect to the data domain involved. At times outlier would lead to different insights from the data. So, in this case, the preferred approach would be to feed the outlier data into the generic processing engine to reveal different insights.
Data augmentation is usually not preferred by many NLP engines; however, this is important to improve the precision/recall of the feature extraction. The preferred approach would be to ask the vendor to provide a list of official parts and service names from their database. These can then subsequently be stored as lookup value to improve the accuracy while preparing feature extraction process.
Feature extraction for opinion phrase is very interesting and always challenging with unstructured data. The usual weapon here is the POS tagger and subsequent to that is Grammar chunk pattern filter.
e.g. phrase “keyboard is good”, “monitor is blur”
The process here is a list of chunker patterns like Noun-Verb, Adj-Verb… etc to identify the opinion phrase from the underlying sentence.
The ideal approach here would be to run iterations to capture all types of phrases. Later on one needs to verify selected feature against proprietary parts/service lookup database for accuracy and flag the sentence for further processing in the pipe.
A similar process needs to be followed to select candidate sentence for wishful items, loyal and outlier items. Once a sentence is identified, a sentiment analysis is run for each sentence and a score calibrated. At this stage, the data points for next level analysis report is generated and finalized.
Technology Stack
The technology stack can include the following:
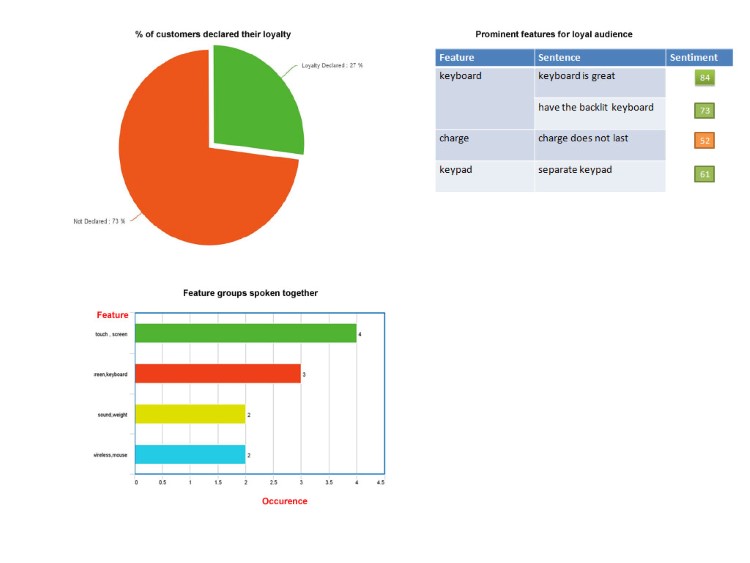
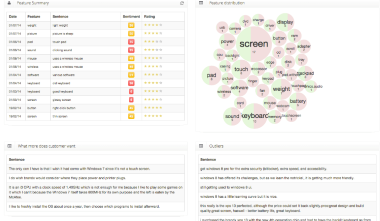
Python Nltk Apache Storm Postgres D3.js OpenNLP SAMPLE REPORTS: Following are some sample reports with actionable insights generated by the NLP engine. Armed with such insightful reports, businesses can either rectify problems or further improve their product or service offering.
Author Bio
Gomes Subramaniam