
How semantic engines can enhance the capabilities of a content management system by providing more intelligent metadata?
Semantics And Semantic Web
In linguistics, semantics is a research field about how meaning is constructed in the human mind, from words and sentences. One of the fundamental differences between natural languages and programming languages is that in computing, we assume that each sentence (or a program statement) is composed in a precise fashion, from the meanings of the programming keywords. Thus, meaning in computing can be formally constructed. Such a strong claim is difficult to maintain for natural language where the meaning of words and phrases is known to change over time, and where competing meanings (ambiguities) are often resolved through applying other knowledge (“context”).
“The main purpose of the Semantic Web is driving the evolution of the current Web by enabling users to find, share, and combine information more easily. Humans are capable of using the Web to carry out tasks such as finding the German translation for “eight days”, reserving a library book, and searching for the lowest price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be readily interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web” — Wikipedia The notion of Semantic Web attempts to bring formal knowledge representation and natural language understanding closer to each other, in order to make it possible to represent and encode everyday knowledge in a way that is processable and computable by machines.
Vocabularies - Ontologies, RDF
Semantic Web is powered by a mix of natural language processing capabilities, the use of controlled Web vocabularies (ontologies) and various semantic data sets to build applications for a specific use.
An ontology provides the vocabulary (or labels) for referring to the terms in a particular subject area, as well as the logical statements that describe what the terms are, how they are related to each other, etc. The core feature of ontologies is the possibility to define formal models of knowledge domains by combining any type and amount of semantic structures (such as taxonomies, mereonomies, non-hierarchical relations such as equals and opposites) on the basis of relationships between “things” or entities. All such “entities” are then referenced by identifiers complying to a uniform mechanism, i.e., Uniform Resource Identifiers (URI). Ontologies provide a number of useful features for knowledge-based intelligent systems, knowledge representation and engineering.
In order to define the semantics of knowledge and content used in these systems, several languages were developed, such as Resource Description Framework (RDF), Web Ontology Language (OWL), and more.
RDF is the main formalism for rendering Web ontologies. It belongs to a family of World Wide Web Consortium (W3C) specifications for representing information on the Web. It offers a simple graph model, which consists of nodes (i.e. resources or literals) and binary relations (i.e. statements) (c.f. http://www.w3.org/RDF/). The RDF data model exploits a recurring linguistic paradigm in Western languages by representing all facts as subject-predicate-object expressions, called triples. In an RDF triple, subject and predicate represent resources identified by URIs, while the object can either identify a resource or a literal value.
Since the object of one resource triple can be the subject of one or more other triples, the resulting triple set forms a graph in which resources represent nodes and arcs depend on their role in each triple.
For example, the following diagram is a representation of an ontology for sports developed by the BBC:
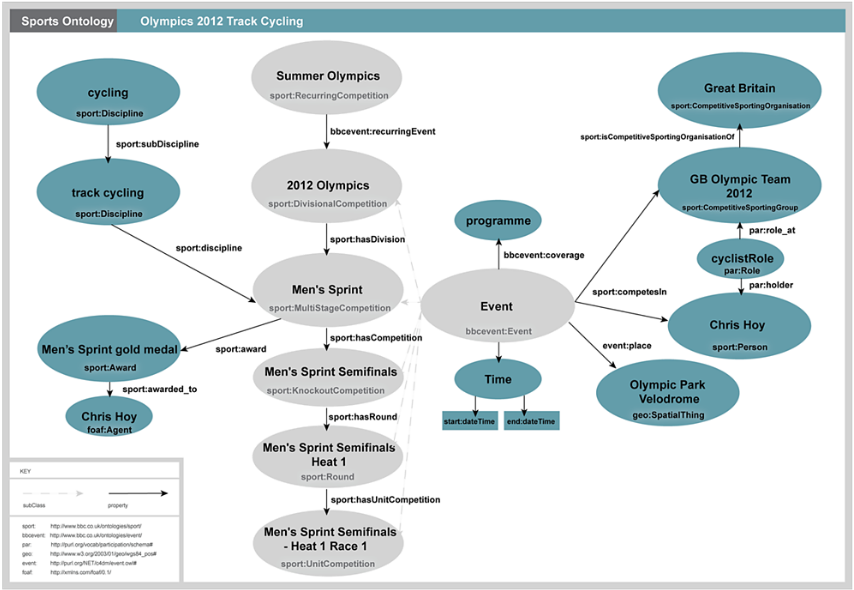
The corresponding RDF can be found here: http://www.bbc.co.uk/ontologies/sport
Semantic Content Management Systems
Content Management Systems (CMSs) provide a platform to store, retrieve, browse and search for content stored in the form of documents, or files in various formats. Conventional CMSs however, provided only rudimentary metadata for each content element, and therefore searching for content in such systems was only based on direct keyword or pattern matches. Semantic Content Management Systems differ from conventional CMSs in the following ways:
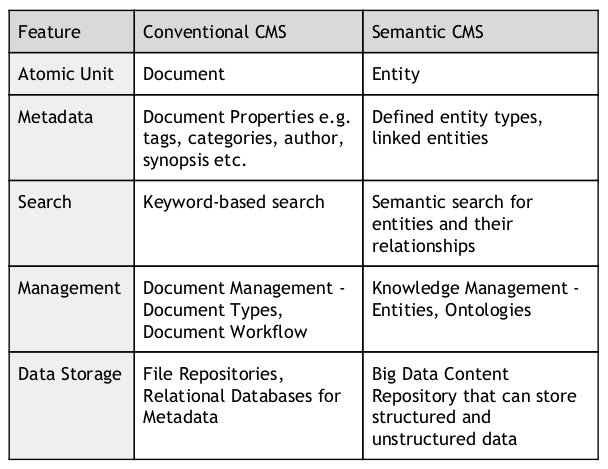
Semantic CMS Requirements
The ideal requirements of a Semantic CMS are as follows:
Common Vocabulary- This requirement is about standardizing the terminology and ensuring a common language for all semantic features across different implementations. Examples of common vocabularies are external ontologies, taxonomies, thesauri, which have the ability to provide horizontal domain knowledge.
Service Oriented Architecture - The architecture follows a RESTful service approach. The architecture must provide customization and exchangeability of the implementation. Services must be orchestrated/ recomposed to new higher order services by reusing the existing services. Services must access information inside the content repository.
Semantic Lifting and Tagging - The application needs to support different tagging and content lifting techniques, automatically or semi-automatically extracting semantics from structured and unstructured data, making suggestions about annotations, etc.
Semantic Search - The key outcomes of a semantic engine can be observed through semantic query and search functionality of the system. Semantic description of content has ability to improve search capabilities and provide better search results. Several sub-requirements came along with that; for example: distributed querying, support for disambiguation of search, user-friendly RDF querying, a prototype search engine understanding microformats, etc.
Reasoning on Content Items - An important requirement of the semantic engine is the extraction of implicit set of data from the explicit information, residing in the content repositories. In addition, it needs to support semantic consistency checking in the content repository.
Links or Relationships between Content Items - Besides semantic tagging, content items might be linked among each other. This process can be automated by using algorithms that reason on the provided tags and ontologies. As linking of content items is already a standard technique in CMS, the Semantic CMS should provide new mechanisms to support automatic link creation, instance linking, linked data cloud, etc.
Workflows - Conventional CMSs provide mechanisms to represent and manage the workflows of content. The expectation of Semantic CMSs is to support the handling of content workflows by using semantic information associated with the content. For example, semantic information can be used to determine the current state of a specific content in a given workflow. The Semantic CMS should provide workflows for semantic actions, which are similar to content workflows. In addition, it should support customizable workflows, intelligent content workflows that are configured based on workflow organization and hierarchy, etc.
Change Management, Versions and Audit - Existing CMSs provide mechanisms to support tasks such as change management, versions and audit. Hence, the Semantic CMS should be aware of content changes and provide solutions to validate semantic data. It should provide change management notifications, mechanisms for change tracking, trust management, role management, revision of content, policies for accessing the data user authentication, etc.
Multi-Lingual Support - The Semantic CMS should be aware of content in different languages and provide functions to reason about information even if they are created in different languages.
Security - Access to the content should be configured by using fine grade access control, e.g. flags such as "reasoning-allowed" or "linkable-with", instead of traditional "read-only" or"no-deletion". The Semantic CMS should also support integration of permissions, roles and group models, policies for accessing the data, user authentication; roles management, trust management, etc.
Semantic CMS Solution Architecture
To address the ideal requirements listed above, the recommended architecture of a Semantic CMS is illustrated in the diagram below:
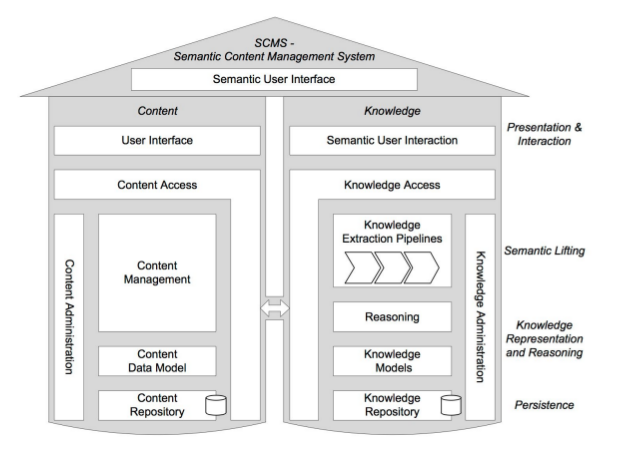 The architecture consists of two pillars:
The architecture consists of two pillars:
Content - consisting of a big data Content Repository that stores all types of structured and unstructured data, with a Content Data Model, Content Management Application and a user interface that provides access to features that a conventional CMS would provide, as well as a Content Administration interface Knowledge - a semantic engine that provides a Knowledge Repository, Knowledge Models, Reasoning and Knowledge Extraction Pipelines and a Semantic User Interface for accessing semantic features of the content, as well as a Knowledge Administration interface The two pillars are connected to each other via the Content Access and Knowledge Access layers.
Technology Platform
The architecture described above uses a set of open source technologies that provide the two pillars of the architecture:
Apache Solr - a persistent document store that forms the Content Hub, and provides the following features:
- Advanced Full-Text Search Capabilities
- Optimized for High Volume Web Traffic
- Standards Based Open Interfaces - XML, JSON and HTTP
- Comprehensive HTML Administration Interfaces
- Server statistics exposed over JMX for monitoring
- Linearly scalable, auto index replication, auto failover and recovery
- Near Real-time indexing
- Flexible and Adaptable with XML configuration
- Extensible Plugin Architecture
Apache Stanbo - a semantic engine providing the following features:
- Content enhancements provided via natural language processing, metadata extraction and linking named entities to public or private entity repositories
- An Ontology Manager to manage the ontologies used
- An Entity Hub component that caches and manages local indexes of repositories such as DBPedia as well as custom data (e.g. product descriptions, contact data, specialized topic thesauri)
- Semantic Indexing facilities during text based document submission and semantic search together with faceted search capability on the documents
- A Fact Store that stores relations between entities identified by their URIs. This relation between two entities is called a fact.
Case Studies The Semantic CMS architecture has been widely used in public and private applications. The following are some notable examples:
Semantic Tourism Applications
- Semantic technologies based on Apache Stanbol have been used in systems that manage knowledge in the tourism industry. Semantic features help product managers to analyse hotel information and tour descriptions, and better retrieve the information.
- The objective of the system is to automatically generate additional information that better describes tour attributes and improves the quality of tour content.
- For the content manager of a tour operator, who is not meant to or does not wish to maintain complex content, the systems provide an option of signing in and editing defined text sections and adding additional information to them.
Semantic Publishing Applications
- These applications provide features for adding semantic information while changing or integrating new content in the publisher’s repository
- Once the annotation phase is completed, all semantic entities are extracted and resulting metadata are saved into the Semantic CMS
- Then during content retrieval, the applications would allow users to not only search for content based on normal text search, but also find related documents that are semantically related based on the entities contained in them
Semantic Healthcare Applications
- Healthcare Semantic CMS applications store health related documents and enhance the documents by using entity extraction and relationships
- Once the content enhancement process is completed, additional knowledge is retrieved from external content hubs for each of the extracted entities, thereby providing useful additional information that is related to the document being indexed, such as related diseases, specific drugs or symptoms
- As a result, documents can be searched or retrieved from the Semantic CMS, based on all related information that is directly or indirectly related to the entities contained in the documents
References
The following references were used to collate information in this document:
Semantic Web on Wikipedia - http://en.wikipedia.org/wiki/Semantic_Web
The BBC Ontologies - http://www.bbc.co.uk/ontologies
Apache Stanbol - https://stanbol.apache.org
Developing Semantic CMS Applications - The IKS Handbook 2013