

Airflow is the perfect choice for Data Pipelines i.e ETL orchestration and scheduling. It is widely adopted and popular for creating future proof data pipelines. It provides back-filling, versioning and lineage with power of Functional Abstraction.
Operator defines a single in a workflow, DAG is a set of Tasks. Operator generally runs Independently, In fact, they may run on completely two different machines. If you are Data Engineer and worked with Apache Spark or Apache Drill, you would probably know What is DAG! Concept is the same at Airflow also.
Build Data Pipelines which are:
- Idempotent
- Deterministic
- Has no side-effects
- Use immutable sources and destinations
- Don’t do update, upsert, append or delete
Modularity & Scalability is the main goal of Functional Data Pipelines.
If you have worked with Functional Programming with Haskell, Scala, Erlang or Now Kotlin, you will wonder that this is what we are doing in Functional programming and above points are feature of Functional Programming, Yes! You’re right. Functional Programming is the future and powerful tool.
If you have ETL / Data Lake / Streaming Infrastructure as a Part of Data Engineering Platform, you must have Hadoop / Spark Cluster with some distribution like Hortonworks, MapR, Cloudera etc. So I am going to talk about How you can utilize the same infrastructure where you have Apache Hadoop / Apache Spark Cluster and you leverage that to build Airflow Cluster and Scale it up.
When you have many ETL Jobs and would like to orchestrate and schedule with some Scheduling tools, then you have couple of choices such as Oozie, Luigi and Airflow. Oozie is XML based and We are in 2019! :), Luigi is almost thrown out after Airflow has born in Airbnb.
Why Airflow not Luigi?
- Airflow has own scheduler where Luigi requires to sync tasks in cron job
- With Luigi, the UI Navigation is challenge
- Task Creation is difficult at Luigi
- Luigi is not Scalable due to tight coupling with Cron jobs
- Re-running pipeline is not possible at Luigi
- Luigi doesn’t support distributed execution as it doesn’t scale up well
Before Airflow, I have used Luigi for maintaining workflow of Machine Learning models with Scikit-learn, Numpy, Pandas, Theano etc.
Read more:
How to Setup Airflow Multi-Node Cluster with Celery & RabbitMQ
Yeah so, coming to the main point.
How to setup Airflow Multi node cluster on Hadoop Spark Cluster so Airflow can trigger Spark / Hive / Hadoop Map Reduce jobs and does orchestration and scheduling.
Let’s do it!
You have to use airflow-ambari-mpack (Apache Airflow management pack for Apache Ambari), I have used open source implementation by FOSS Contributor https://github.com/miho120/ambari-airflow-mpack , Thank you for contribution.
Steps to follow:
From earlier blog post, You have to go through steps 1 to 4 to install RabbitMQ and other packages.
Ref. How to setup Airflow Multi node cluster on Hadoop Spark Cluster so Airflow can trigger Spark / Hive / Hadoop Map Reduce jobs and does orchestration and scheduling.
- Installing Apache MPack for Airflow
a. git clone https://github.com/miho120/ambari-mpack.git
b. stop ambari server
c. install the apache mpack for airflow on ambari server
d. start ambari server- Add Airflow Service at Ambari
Once above steps are been successfully completed. You can open Ambari UI
http:// :8080
Open Ambari UI, Click on Actions -> Add Service
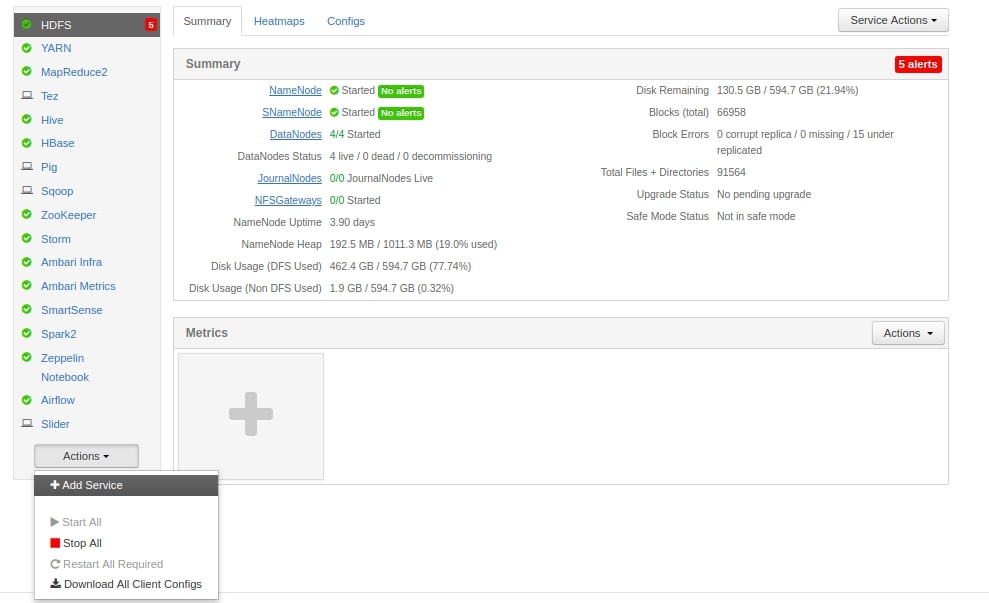
If step 1, is successfully done then you would able to see Airflow as a part of Ambari Service.
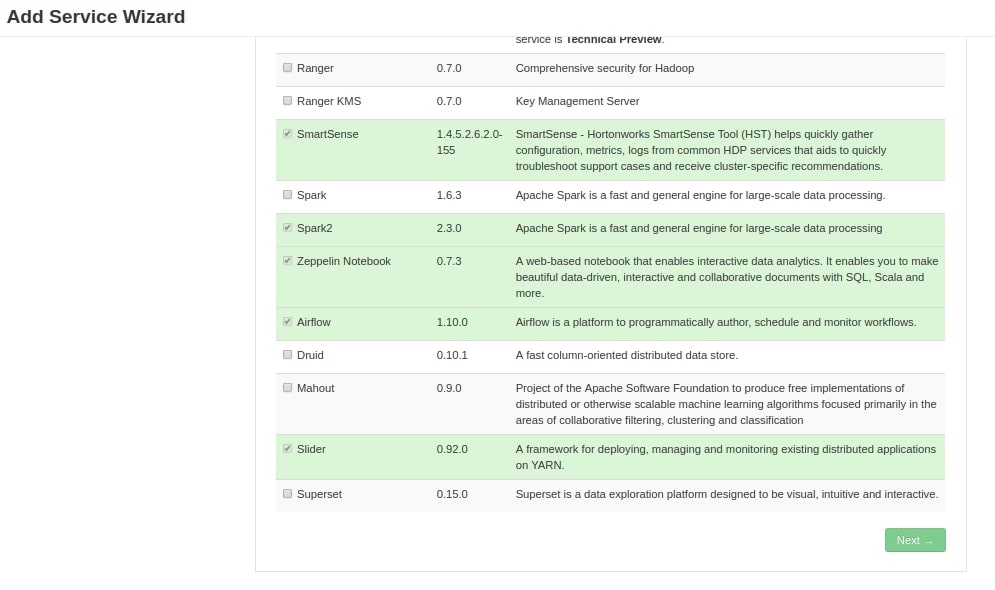
You have to select on which node you would like install webserver, scheduler and worker. My recommendation would be to install Airflow webserver, scheduler on Master Node i.e Name Node and on Install Worker on Data Nodes.
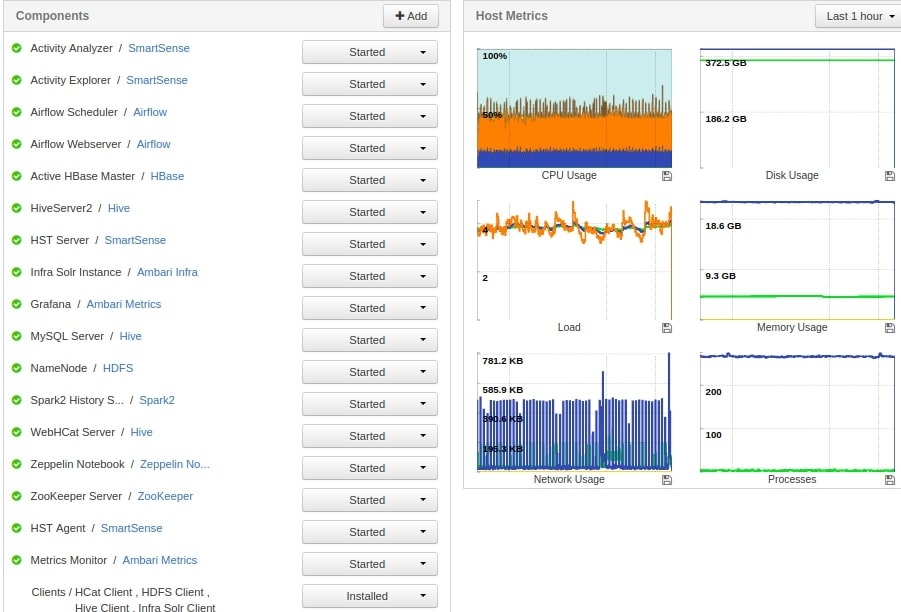
So as you can see in above image, Airflow Webserver and Airflow Scheduler is installed on Name Node of the Hadoop / Spark Cluster.
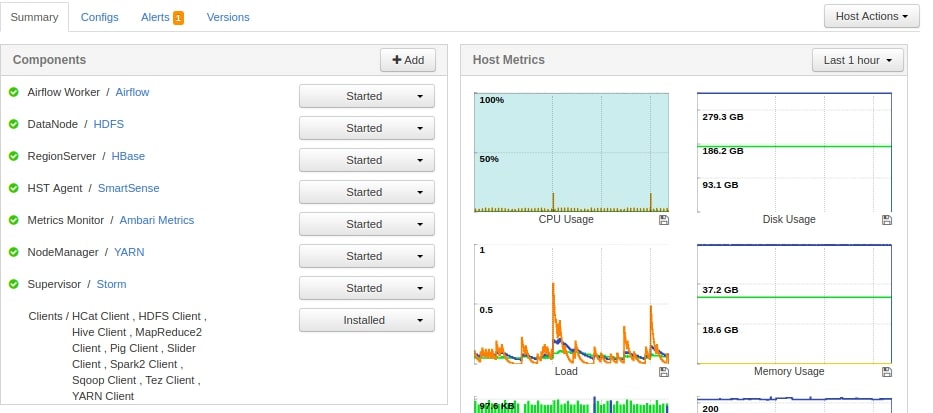
As you can see in above screenshot that Airflow Worker service is installed on Data Nodes of the cluster. In total, for this example. I have got 3 Worker nodes on my 3 Data Nodes.
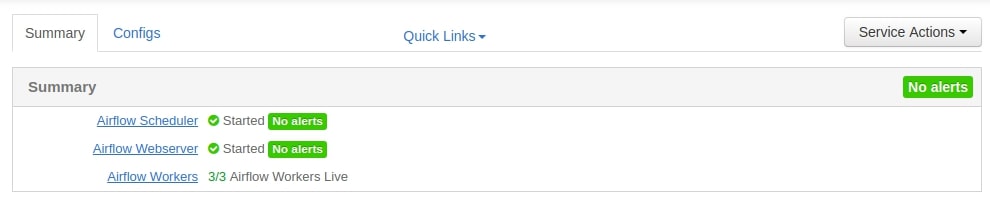
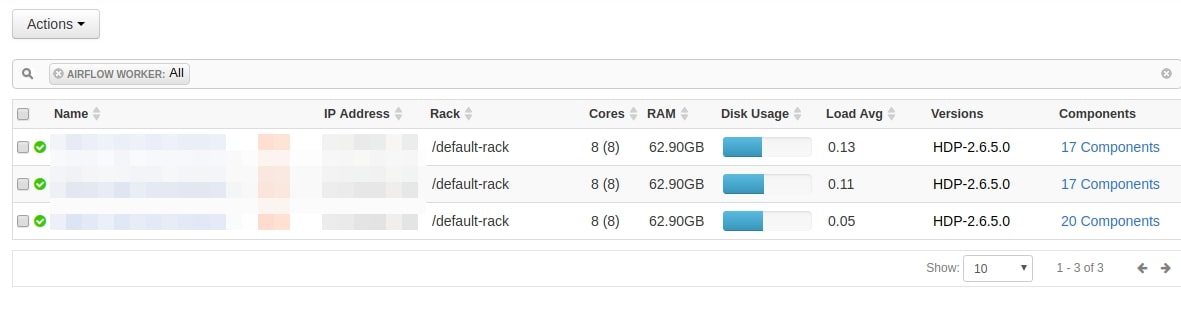
You can add worker nodes as many as you want, you can add / remove workers whenever you want for scale up / scale down. This strategy can scale horizontally + vertically.
Airflow Configuration at Ambari:
Click on Airflow Service and then at Config in Ambari UI.
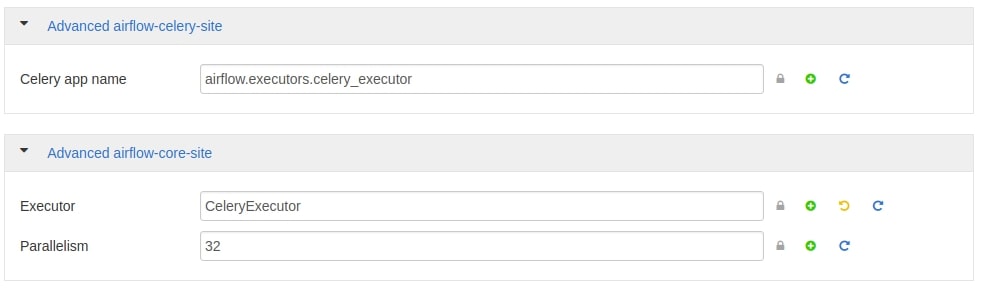
- Change the Executor
executor = CeleryExecutor
Under Advanced airflow-core-site, mention Executor as CeleryExecutor
- SQL Alchemy Connection
sql_alchemy_conn = postgresql+psycopg2://airflow:airflow@{HOSTNAME}/airflow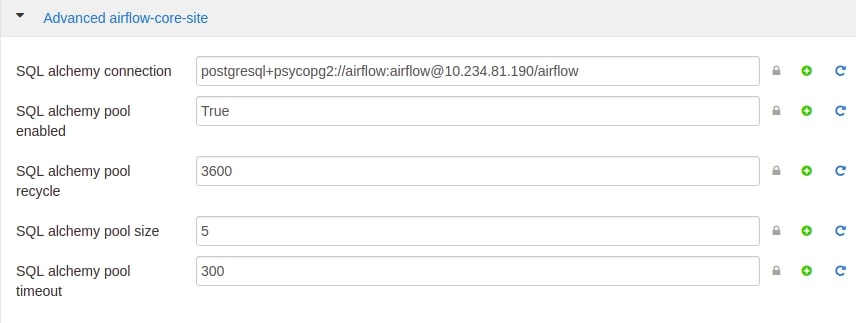
Change the SQL Alchemy Connection with postgresql connection, example is given above.
- Broker URL
broker_url= pyamqp://guest:guest@{RabbitMQ-HOSTNAME}:5672/
celery_result_backend = db+postgresql://airflow:airflow@{HOSTNAME}/airflow
- Others
dags_are_paused_at_creation = True
load_examples = False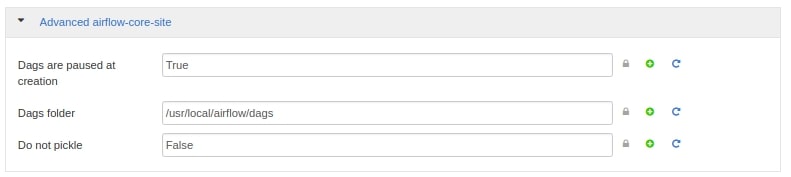
After all this changes are made at Ambari Airflow Configuration, Ambari will ask you to do restart for all affected services, please do restart the services and do click on Service Actions -> InitDB.
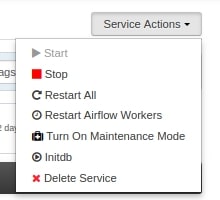
and then start the airflow service. You should be good now with Multi Node Airflow Cluster.
Some of the Check list to verify the services for Multi Node Airflow Cluster:
- RabbitMQ Queues should be running
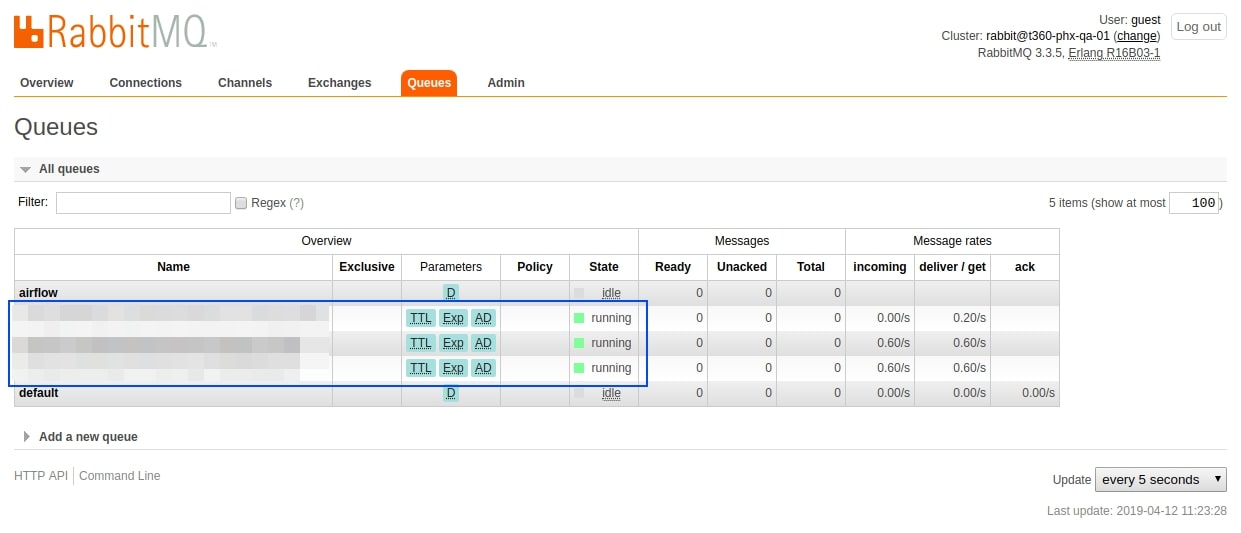
- RabbitMQ Connections should be active
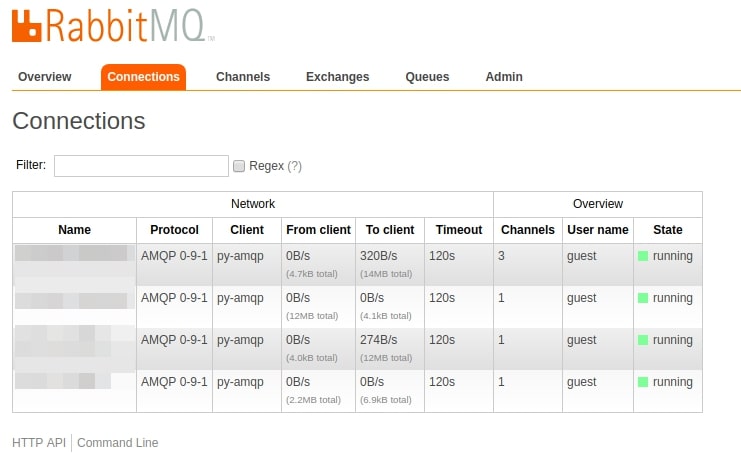
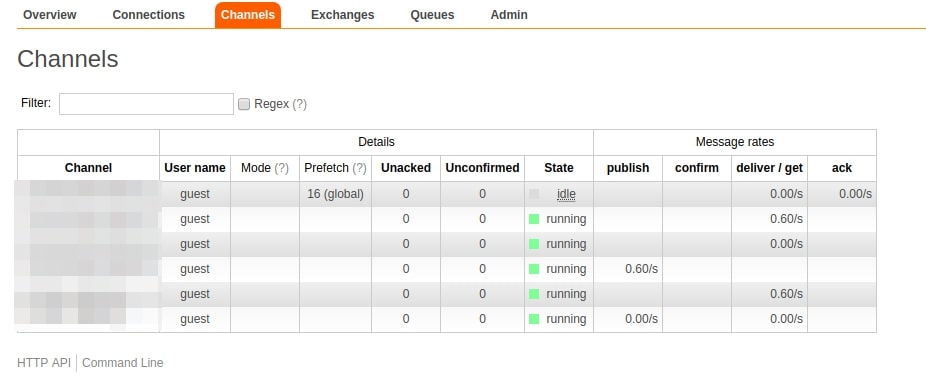
- RabbitMQ Channels should be running
- Monitor Celery Flower
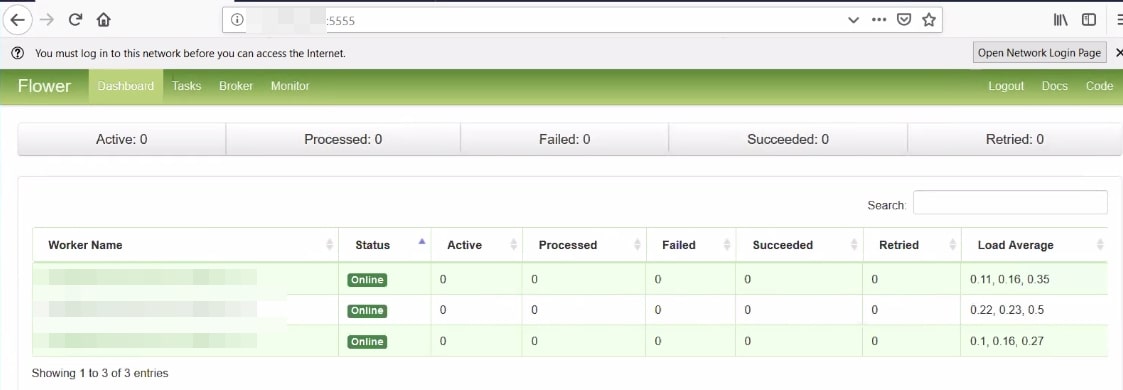
You can also see here that 3 Workers are online and you can monitor the single unit of Celery “task” here.
Read more on Celery Flower: https://flower.readthedocs.io/en/latest/
Note that you can also run “Celery Flower”, a web UI built on top of Celery, to monitor your workers. You can use the shortcut command airflow flower to start a Flower web server.
nohup airflow flower >> /var/local/airflow/logs/flower.logs &Yeah, here we go!, We are done with Setup & Configuration of Multi Node Airflow Cluster on top on Ambari HDP Hadoop / Spark Cluster.
Now Question is, this is what — that straight forward or did I face some challenges while doing this setup. Yes, I did face some of the challenges and that I will share in next blog post.