

ABSTRACT
This case study outlines the architecture that was implemented to address the requirements of a government department that handles a large number of correspondence documents that need to be archived. With stringent performance requirements, we implemented the solution using Oodebe - a modular data processing framework built on node.js and exceeded the required performance levels by over 2 times.
THE REQUIREMENTS
The customer was a government department that handles a large number of correspondence documents that are generated by several thousand users through various consumer facing and internal applications. For regulatory compliance, it is required to maintain an archive of all correspondence in the form of print files along with metadata. Basic technical requirements were as follows:
- Scalability of archive for large number of documents without compromising on performance
- Tough performance criteria for batch and online operations
- Document storage constraints including access control, physical separation, version control and workflow rules
- Complex search operations including fuzzy search and proximity
- Web services interfaces for all batch and online operations
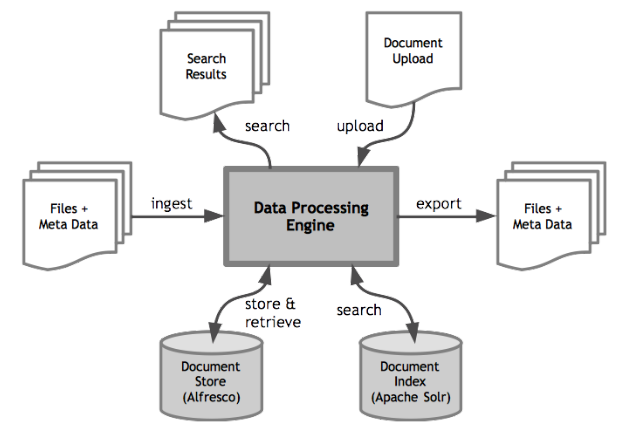
Of these requirements, the most critical requirements were the scalability and performance of operations handled by the Data Processing Engine. There were two types of operations that the Data Processing Engine needed to perform:
- Batch operation : for ingestion and export of multiple documents
- Online operation : for upload and search for individual documents
- There were already over 500 million historical documents that needed to be migrated into the new archive. In addition 200,000 new and updated documents were required to be ingested daily. Online operations were used to search and upload individual documents and were used continuously throughout the day by various consumer facing applications.
- The performance levels required for various operations were quite stringent, and were specified as follows:
THE CHALLENGES
The functional requirements resembled a standard Enterprise Content Management application and hence the customer had already chosen Alfresco - the open source ECM platform. Further, Alfresco already supports indexing of metadata in Apache Solr and hence the search requirements also seemed to be easily addressed. However, there were certain technical challenges that forced us to look beyond the out-of-box features of Alfresco. These were:
- Pre-processing in batch ingestion : For ingesting documents in batches, the process required some pre-processing steps that required parsing through large binary files that contained multiple documents.
- Post-processing in batch export : Similarly during batch export, it required some post-processing steps that included manipulation of the meta data, conversion of data formats using external tools, as well as concatenation of multiple documents into large binary output files.
- Support for advanced search : Though Alfresco has in-built support for Apache Solr, it does not support all advanced search operations that Solr supports.
- Support for SolrCloud : Current version of Alfresco does not support SolrCloud that provides horizontal scalability for Solr out of the box
- Eventual consistency : For high performance of batch operations eventual consistency is a compromise that was considered to beacceptable. This is not supported in Alfresco as it is ACID compliant.
SOLUTION ARCHITECTURE
- To address these challenges, we implemented an independent application for the Data Processing Engine (DPE)The DPE application would handle all the pre-processing and post-processing operations
- Alfresco would be used as a data store so as to handle all the ECM requirements including access control, physical separation, version control and workflow rules
- Instead of using the inbuilt support indexing to Solr directly from Alfresco, the DPE would index documents to Apache SolrCloud so as to allow horizontal scalability of Solr
- All online operations would be handled by implementing web services APIs for document upload and search requests. This would allow support of all advanced features of Apache Solr
- The DPE would use queuing and prioritization of operations to provide eventual consistency in batch operations
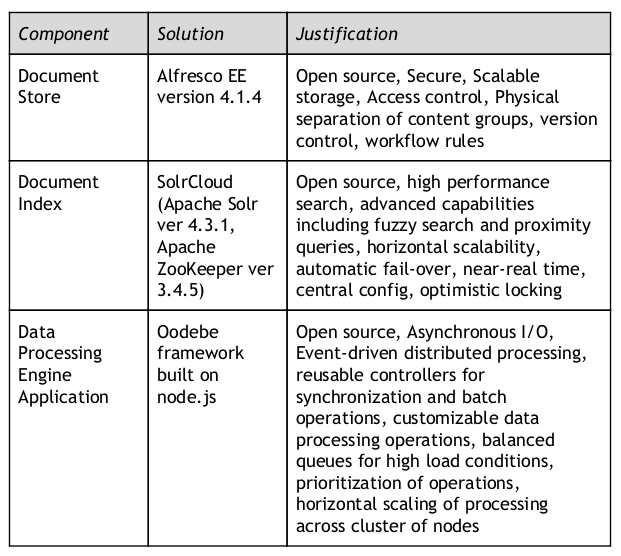
TECHNOLOGY STACK
The following technologies were chosen for implementing the Data Processing Engine:
PROOF OF CONCEPT
To be able to handle the stringent performance requirements, it was mandatory to choose a platform that allows very high level of concurrency to be able to process a large number of documents simultaneously.
To handle this high concurrency, the architecture of the Data Processing Engine needed to:
- Handle multiple documents simultaneously with minimal CPU utilization
- Be horizontally scalable across multiple CPUs on the same system as well as across a cluster of processing nodes
We proposed using Oodebe - the node.js based synchronization engine.
Node.js uses asynchronous I/O that is perfectly suited for handling a large number of concurrent operations that involve I/O wait times. See this articl for a comparison between single threaded node.js asynchronous I/O with the multithreaded synchronous I/O in vanilla Java EE. Further, Oodebe builds on top of node.js to provide for horizontal scalability with a modular, message-driven architecture.
However, the customer was not familiar with node.js nor with Oodebe and hence was pushing for implementation on their existing Java EE platform. To convince them about the scalability of Oodebe and node.js, we first implemented a proof-of-concept.
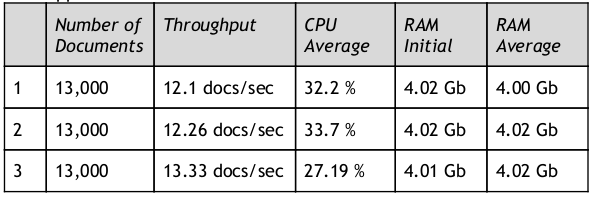
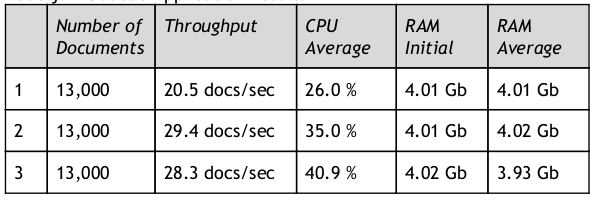
We implemented a single operation of indexing documents into Alfresco using Alfresco’s REST API in two different applications - one using their existing Java EE platform and one using Oodebe and node.js. Then we tested the performance of both these applications by running a series of tests for ingestion of the same set of documents on a single thread/process.
The results were as follows:
Java Application Results
Node.js + Oodebe Application Results
Performance Comparison
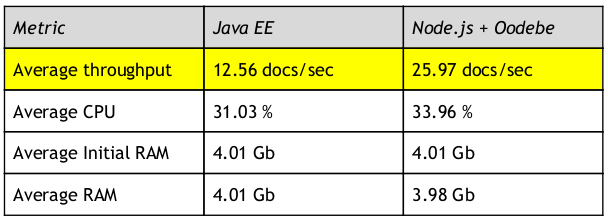
Based on the results of the proof of concept, we managed to convince the customer to approve the node.js and Oodebe based architecture.
APPLICATION ARCHITECHTURE
The Data Processing Engine application architecture consisted of the following modules: 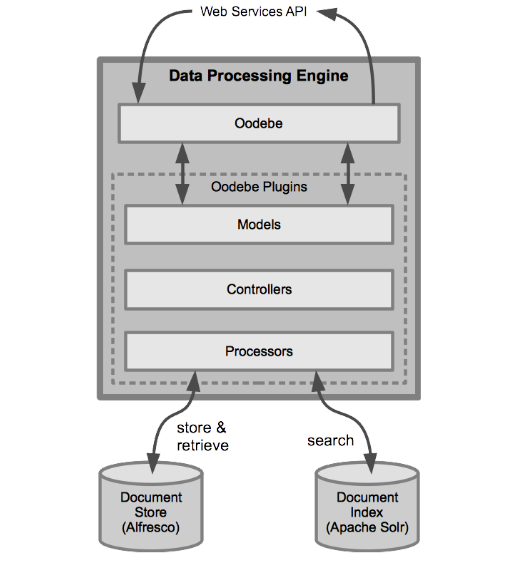
Oodebe
- Oodebe is a modular, message-driven framework based on node.js
- Provides web services APIs that can be mapped to customized controller plugins by defining application specific models
- Reusable controller modules provide batch and online operations
- Reusable processor modules provide support for various databases including MySQL, Oracle, MS-SQL, Hadoop, MongoDB, Cassandra, Apache Solr, Neo4j etc.
- Custom controllers and processors can be added in the form of plugins
- Leverages the asynchronous I/O model of node.js to provide large number of concurrent operations
- Horizontal scalability using multiple workers on a single server as well as across multiple nodes in a cluster
- Event-driven, message-based distributed processing architecture
- Built-in features for high availability and fault tolerance
- Open source license with full source code on GitHub
Models
- A model represents a group of API endpoints
- It maps each API endpoint to a controller and a set of processors
Controllers
- Reusable components that co-ordinate the execution of an API
- Controllers can use one or more processors for implementing the API’s required operations
- Each controller creates an event bus for coordinating execution of processor instances
- Built-in batch controller extended for implementing custom batch operations for ingestion and export
Processors
- Processors encapsulate various operations or interfaces to external systems
- Custom processors created for interface to Alfresco, Apache Solr, pre-processing and post-processing operations
RESULTS
The final implementation of the Data Processing Engine was deployed and extensive performance tests were carried out on a clustered setup with two DPE nodes.
The architecture was successfully deployed and performance tests conducted by the customer exceeded the required limits by more than 2 times.
The following table summarizes the results of the performance tests:
Results of Performance Tests
| Operation | Volume | Required Speed | Actual Speed (per node) |
|---|---|---|---|
| Historical Data | 500 mil docs | - | - |
| Batch Ingestion | 200,000 docs/day | 25 docs/sec | 63 docs/sec |
| Batch Export | 200,000 docs/day | 25 docs/sec | 80.65 docs/sec |
| Online Search | 25 requests/sec | under 2 secs | 262 msec |
| Online Upload | 25,000 docs/day | under 2 secs | 686 msec |